Depuis plusieurs mois déjà, des membres du réseau ATONET discutent d'un format d'échange de documents électroniques visant à faire la transition entre les formats propriétaires des logiciels et un format XML basé sur les recommandations du Text Encoding Initiative (TEI). Les logiciels considérés jusqu'à maintenant sont Alceste, Astartex, DTM, Lexico et SATO. Le format Astartex étant encore en évolution, on a surtout considéré les formats des logiciels faisant déjà l'objet d'une diffusion publique.
Dans un premier temps, on s'est concentré sur la définition d'un format qui n'impliquerait aucune modification aux logiciels existants. Pour ce faire, on a développé des passerelles permettant de convertir les formats des corpus entre le format pivot XML-TEI et les formats propriétaires. L'objectif à moyen terme, cependant, est de proposer un format qui permettrait d'enrichir les corpus en y injectant les résultats des analyses et annotations produites par les divers logiciels d'analyse textuelle ou par tout autre logiciel pertinent.
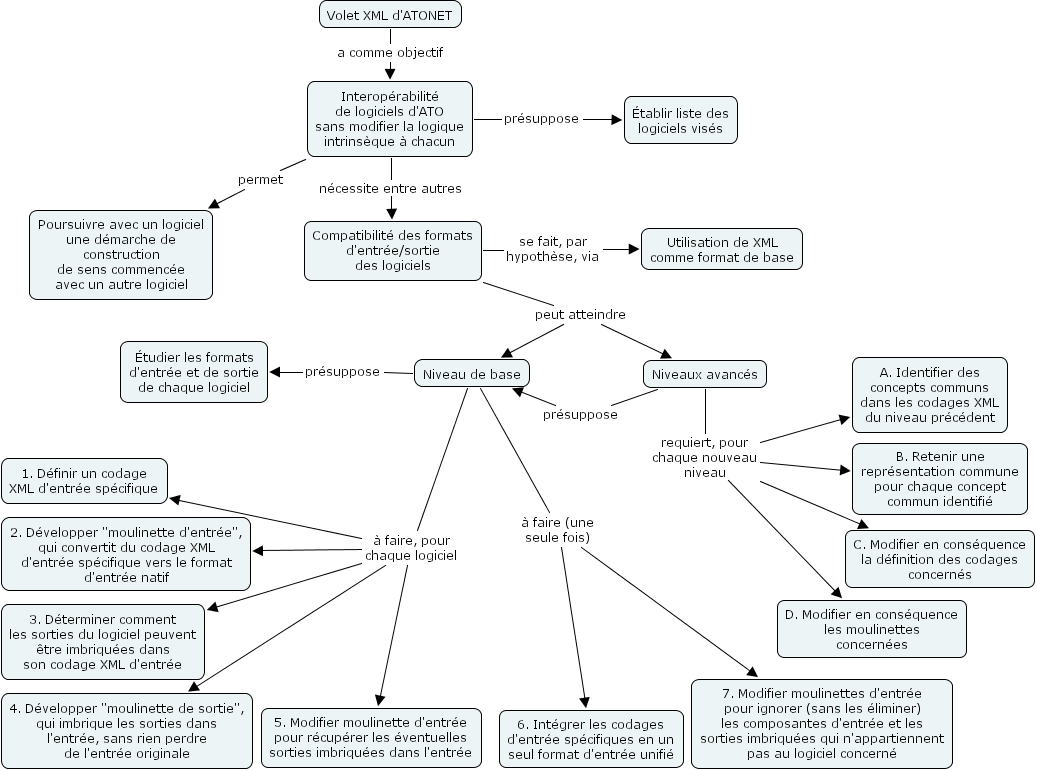
Voici le plan de présentation du compte-rendu de notre travail.
| Exemple de document simple |
|---|
<?xml version="1.0" encoding="iso-8859-1"?> |
<!DOCTYPE Document-simple []> |
<Document-simple> |
<page n="32" />
<paragraphe no="1">
texte libre suivi de
<élément2 attribut1="valeur" attribut2="valeur">
contenu de l'élément 2
</élément2>
<!-- Commentaire qui montre l'entité caractère < -->
</paragraphe>
|
</Document-simple> |
La proposition sera présentée à partir d'un exemple commenté d'un poème de Rimbaud.
| Exemple de texte en XML-TEI avec balises <milestone> |
|---|
<?xml version="1.0" encoding="iso-8859-1"?> |
<!DOCTYPE TEI SYSTEM "..\dtd\tei.dtd" [ <!ENTITY % TEI.header "INCLUDE"> <!ENTITY % TEI.core "INCLUDE"> <!ENTITY % TEI.textstructure "INCLUDE"> <!ENTITY % TEI.analysis "INCLUDE"> <!ENTITY % TEI.iso-fs "INCLUDE"> <!ENTITY % TEI.linking "INCLUDE"> ]> |
<TEI xmlns="http://www.tei-c.org/ns/1.0"> |
<teiHeader>
<fileDesc>
<titleStmt>
<title>Deux poèmes célèbres...</title>
<author>... à compléter</author>
</titleStmt>
<publicationStmt> <p>Publié par...</p></publicationStmt>
<sourceDesc> <p>Texte fourni par ... </p></sourceDesc>
</fileDesc>
<encodingDesc>
<refsDecl>
<p>Les balises «milestone n="valeur-de propriété" unit="nom-de-propriété"»
concernent les mots qui suivent la balise jusqu'à l'apparition d'un nouveau
milestone de même unit. Les références de pagination utilisent les balises
pb (début de page) et lb (début de ligne).</p>
<p>milestone champ symbol "titre" "poème" "signature"</p>
<p>Les instructions de traitement «sato» avec l'attribut «cmd» décrivent les
commandes «alphabets» qui guident le tri alphabétique et le découpage
en mots par SATO pour chacune des langues utilisées dans le corpus.</p>
<?sato cmd="Alphabet fr a b c d e f g h i j k l m n o œ p q r s t u v
w x y z 0 ,0 .0 ¼ ½ ¾ 1 ,1 .1 ¹ 2 ,2 .2 ² 3 ,3 .3 ³ 4 ,4 .4 5 ,5 .5 6 ,6 .6 7
,7 .7 8 ,8 .8 9 ,9 .9 *accent '_ _ ~ ^ ° *séparateur - , : ; . ? ¿ ! ... <
> ( ) [ ] { } « » % $ £ ¢ ¥ # " @ "?>
</refsDecl>
</encodingDesc>
</teiHeader>
|
|
<text> <body> <pb n="rimbaud-le_dormeur_du_val/1"/> <p><lb n="1"/><milestone n="titre" unit="champ"/> Le dormeur du val </p> <p><lb n="2"/><milestone n="poème" unit="champ"/> C'est un trou de verdure où chante une rivière <lb n="3"/>Accrochant follement aux herbes des haillons <lb n="4"/>D'argent ; où le soleil, de la montagne fière, <lb n="5"/>Luit : c'est un petit val qui mousse de rayons.</p> <p><lb n="6"/>Un soldat jeune, bouche ouverte, tête nue, <lb n="7"/>Et la nuque baignant dans le frais cresson bleu, <lb n="8"/>Dort ; il est étendu dans l'herbe, sous la nue, <lb n="9"/>Pâle dans son lit vert où la lumière pleut.</p> <p><lb n="10"/>Les pieds dans les glaïeuls, il dort. Souriant comme <lb n="11"/>Sourirait un enfant malade, il fait un somme : <lb n="12"/>Nature, berce-le chaudement : il a froid. </p> <p><lb n="13"/>Les parfums ne font pas frissonner sa narine ; <lb n="14"/>Il dort dans le soleil, la main sur sa poitrine <lb n="15"/>Tranquille. Il a deux trous rouges au côté droit. </p> <p><lb n="16"/><milestone n="signature" unit="champ"/>Arthur Rimbaud</p> </body> </text> |
|
</TEI> |
Dans cet exemple, on a mis dans des cases séparées diverses composantes du document en format TEI. Examinons-les une à une.
<?xml ... C'est le prologue recommandé pour indiquer que le document est en XML
<!DOCTYPE TEI ... C'est la définition du type de document indiquant ici qu'il s'agit d'un document TEI. Dans cet exemple, on fait référence à une DTD qui se trouve sur le disque local. C'est pour des fins de validation : on peut lancer un parseur XML qui validera le document et indiquera les erreurs éventuelles. En production, on ne contente de référer à une déclaration publique de la DTD standard du TEI. Il est aussi à noter qu'il existe un type de document teiCorpus qui permet de rassembler un ensemble de textes possédant chacun une entête TEI.
<TEI ... Voilà l'élément racine qui porte le nom du type de document annoncé dans le DOCTYPE. L'attribut xmlns signifie que les éléments qui suivent sont, sauf mention contraire, définis dans un espace de noms portant la signature du TEI. Cela permet de ne pas confondre ces noms avec des homographes qui pourraient appartenir à d'autres DTD.
<teiHeader> ... C'est l'entête TEI elle-même composée de plusieurs sections.
La section <fileDesc> contient une sous-section <titleStmt> qui fournit le titre et l'auteur du texte, une sous-section <publicationStmt> et une sous-section <sourceDesc>.
La section <encodingDesc> permet de documenter la codification du texte. En particulier, on y retrouve la sous-section <refsDecl> qui décrit les systèmes référentiels, notamment les balises milestone utilisées pour introduire les variables qui traduisent les balises LEXICO, les propriétés SATO, etc.
Dans cet exemple, on a utilisé une instruction de traitement pour rappeler les règles utilisées par SATO pour découper le texte en mots et produire un tri lexicographique des lexèmes. En fouillant davantage, on pourrait peut-être trouver une façon plus TEI de décrire ces règles.
Plusieurs sections facultatives de l'entête TEI ne sont pas illustrées dans cet exemple. Elles permetttent de conserver un ensemble de métadonnées de description et de classification.
<text> ... C'est ici que débute le texte plein. Dans la section <body>, qui nous intéresse ici plus particulièrement, on peut retrouver, outre le texte plein, un nombre important de balises TEI dont certaines seulement seront interprétées par nos logiciels non-XML. Les autres balises sont supprimées par les passerelles de traduction, ou sont considérées comme des commentaires. Voici la liste des balises prises en compte par notre proposition.
| Exemple de texte en XML-TEI avec balises <milestone> et <w> |
|---|
<?xml version="1.0" encoding="iso-8859-1"?> |
<!DOCTYPE TEI SYSTEM "..\dtd\tei.dtd" [ <!ENTITY % TEI.header "INCLUDE"> <!ENTITY % TEI.core "INCLUDE"> <!ENTITY % TEI.textstructure "INCLUDE"> <!ENTITY % TEI.analysis "INCLUDE"> <!ENTITY % TEI.iso-fs "INCLUDE"> <!ENTITY % TEI.linking "INCLUDE"> ]> |
<TEI xmlns="http://www.tei-c.org/ns/1.0"> |
<teiHeader>
<fileDesc>
<titleStmt>
<title>Deux poèmes célèbres...</title>
<author>... à compléter</author>
</titleStmt>
<publicationStmt> <p>Publié par...</p></publicationStmt>
<sourceDesc> <p>Texte fourni par ... </p></sourceDesc>
</fileDesc>
<encodingDesc>
<refsDecl>
<p>Les balises «milestone n="valeur-de propriété" unit="nom-de-propriété"»
concernent les mots qui suivent la balise jusqu'à l'apparition d'un nouveau
milestone de même unit. Les références de pagination utilisent les balises
pb (début de page), lb(début de ligne) et w (word).</p>
<p>milestone champ symbol "titre" "poème" "signature"</p>
<p>Les instructions de traitement «sato» avec l'attribut «cmd» décrivent les
commandes «alphabets» qui guident le tri alphabétique et le découpage
en mots par SATO pour chacune des langues utilisées dans le corpus.</p>
<?sato cmd="Alphabet fr a b c d e f g h i j k l m n o œ p q r s t u v
w x y z 0 ,0 .0 ¼ ½ ¾ 1 ,1 .1 ¹ 2 ,2 .2 ² 3 ,3 .3 ³ 4 ,4 .4 5 ,5 .5 6 ,6 .6 7
,7 .7 8 ,8 .8 9 ,9 .9 *accent '_ _ ~ ^ ° *séparateur - , : ; . ? ¿ ! ... <
> ( ) [ ] { } « » % $ £ ¢ ¥ # " @ "?>
</refsDecl>
</encodingDesc>
</teiHeader>
|
|
<text> <body> <pb n="rimbaud-le_dormeur_du_val/1"/> <p><lb n="1"/><milestone n="titre" unit="champ"/> <w xml:id="w2" n="1">Le</w> <w xml:id="w3" n="2">dormeur</w> <w xml:id="w4" n="3">du</w> <w xml:id="w5" n="4">val</w> </p> <p><lb n="2"/><milestone n="poème" unit="champ"/> <w xml:id="w7" n="1">C'</w><w xml:id="w8" n="2">est</w> <w xml:id="w9" n="3">un</w> <w xml:id="w10" n="4">trou</w> <w xml:id="w11" n="5">de</w> <w xml:id="w12" n="6">verdure</w> <w xml:id="w13" n="7">où</w> <w xml:id="w14" n="8">chante</w> <w xml:id="w15" n="9">une</w> <w xml:id="w16" n="10">rivière</w> <lb n="3"/><w xml:id="w18" n="1">Accrochant</w> <w xml:id="w19" n="2">follement</w> <w xml:id="w20" n="3">aux</w> <w xml:id="w21" n="4">herbes</w> <w xml:id="w22" n="5">des</w> <w xml:id="w23" n="6">haillons</w> <lb n="4"/><w xml:id="w25" n="1">D'</w><w xml:id="w26" n="2">argent</w> <w xml:id="w27" n="3">;</w> <w xml:id="w28" n="4">où</w> <w xml:id="w29" n="5">le</w> <w xml:id="w30" n="6">soleil</w><w xml:id="w31" n="7">,</w> <w xml:id="w32" n="8">de</w> <w xml:id="w33" n="9">la</w> <w xml:id="w34" n="10">montagne</w> <w xml:id="w35" n="11">fière</w><w xml:id="w36" n="12">,</w> <lb n="5"/><w xml:id="w38" n="1">Luit</w> <w xml:id="w39" n="2">:</w> <w xml:id="w40" n="3">c'</w><w xml:id="w41" n="4">est</w> <w xml:id="w42" n="5">un</w> <w xml:id="w43" n="6">petit</w> <w xml:id="w44" n="7">val</w> <w xml:id="w45" n="8">qui</w> <w xml:id="w46" n="9">mousse</w> <w xml:id="w47" n="10">de</w> <w xml:id="w48" n="11">rayons</w><w xml:id="w49" n="12">.</w> </p> <body> </text> |
| </TEI> |
Examinons les composantes de ce deuxième format.
<?xml ... Prologue XML
<!DOCTYPE TEI ... C'est la définition du type de document. Identique à la proposition de base.
<TEI ... Élément racine. Identique à la proposition de base
<teiHeader> ... Entête TEI. Identique à la proposition de base, à part la mention de la balise w;
<text> ... Texte plein. Le découpage en mots est marqué par la paire de balises
<w> </w>.
Chaque mot possède un identificateur unique
xml:id="w2"...
qui permet de le référencer. On peut non seulement pointer de façon unique chacun des token, mais on on peut aussi utiliser des balises, telles la balise TEI span, qui permettent de désigner des segments de texte : par exemple,
<span value="métaphore" id="s33_35" from="#w33" to="#w35"/>
désigne le syntagme la montagne fière. Comme on a donné un identifieur unique au span, on pourra également y faire référence.
Les logiciels qui procèdent à des analyses lexicométriques doivent nécessairement découper le texte en token. Dans cette représentation, on ne fait que rendre explicite ce découpage. Il serait souhaitable que ce découpage, s'il est déjà marqué dans le corpus, puisse être respecté par les logiciels de traitement lexical afin de produire des annotations compatibles.
Le découpage en mots identifiés de façon unique facilite grandement la possibilité de l'annotation déportée résidant sur des fichiers d'annotations séparés. Voici un exemple de fichier d'annotations produit par le logiciel SATO.
| Exemple de fichier d'annotations déportées |
|---|
<?xml version="1.0" encoding="iso-8859-1"?> |
<!DOCTYPE TEI SYSTEM "..\dtd\tei.dtd" [ <!ENTITY % TEI.header "INCLUDE"> <!ENTITY % TEI.core "INCLUDE"> <!ENTITY % TEI.textstructure "INCLUDE"> <!ENTITY % TEI.analysis "INCLUDE"> <!ENTITY % TEI.iso-fs "INCLUDE"> <!ENTITY % TEI.linking "INCLUDE"> ]> |
<TEI xmlns="http://www.tei-c.org/ns/1.0"> |
<teiHeader> <fileDesc> <titleStmt> <title>Deux poèmes célèbres...</title> <author>... à compléter</author> </titleStmt> <publicationStmt> <p>Publié par...</p></publicationStmt> <sourceDesc> <p>Texte fourni par ... </p></sourceDesc> </fileDesc> <encodingDesc> <fsdDecl type="prolex" url="poeme_fsd.xml"/> <fsdDecl type="protex" url="poeme_fsd.xml"/> </encodingDesc> </teiHeader> |
<text> <body> <linkGrp type="prop" targFunc="token prolex protex"> <link targets="poemes.xml#w2 #px74 #pw2"> <link targets="poemes.xml#w3 #px41 #pw3"> <link targets="poemes.xml#w4 #px45 #pw4"> <link targets="poemes.xml#w5 #px147 #pw5"> <link targets="poemes.xml#w7 #px22 #pw7"> <link targets="poemes.xml#w8 #px51 #pw8"> <link targets="poemes.xml#w9 #px143 #pw9"> <link targets="poemes.xml#w10 #px140 #pw10"> <link targets="poemes.xml#w11 #px36 #pw11"> <link targets="poemes.xml#w12 #px149 #pw12"> <link targets="poemes.xml#w13 #px102 #pw13"> <link targets="poemes.xml#w14 #px25 #pw14"> <link targets="poemes.xml#w15 #px144 #pw15"> <link targets="poemes.xml#w16 #px119 #pw16"> <link targets="poemes.xml#w18 #px7 #pw18"> <link targets="poemes.xml#w19 #px59 #pw19"> <link targets="poemes.xml#w20 #px15 #pw20"> <link targets="poemes.xml#w21 #px67 #pw21"> <link targets="poemes.xml#w22 #px38 #pw22"> <link targets="poemes.xml#w23 #px65 #pw23"> <link targets="poemes.xml#w25 #px34 #pw25"> <link targets="poemes.xml#w26 #px11 #pw26"> <link targets="poemes.xml#w27 #px5 #pw27"> <link targets="poemes.xml#w28 #px102 #pw28"> <link targets="poemes.xml#w29 #px74 #pw29"> <link targets="poemes.xml#w30 #px128 #pw30"> <link targets="poemes.xml#w31 #px1 #pw31"> <link targets="poemes.xml#w32 #px36 #pw32"> <link targets="poemes.xml#w33 #px73 #pw33"> <link targets="poemes.xml#w34 #px87 #pw34"> <link targets="poemes.xml#w35 #px55 #pw35"> <link targets="poemes.xml#w36 #px1 #pw36"> <link targets="poemes.xml#w38 #px80 #pw38"> <link targets="poemes.xml#w39 #px4 #pw39"> <link targets="poemes.xml#w40 #px22 #pw40"> <link targets="poemes.xml#w41 #px51 #pw41"> <link targets="poemes.xml#w42 #px143 #pw42"> <link targets="poemes.xml#w43 #px105 #pw43"> <link targets="poemes.xml#w44 #px147 #pw44"> <link targets="poemes.xml#w45 #px115 #pw45"> <link targets="poemes.xml#w46 #px90 #pw46"> <link targets="poemes.xml#w47 #px36 #pw47"> <link targets="poemes.xml#w48 #px117 #pw48"> <link targets="poemes.xml#w49 #px3 #pw49"> <!-- etc... --> </linkGrp> <p> <fs xml:id="px1" type="prolex" n=", 153 31"> <f name="Alphabet"><symbol value="fr"/></f> <f name="Fréqtot"><numeric value="25"/></f> <f name="Longueur"><numeric value="1"/></f> <f name="Gramr"><symbol value="Pon"/></f> </fs> <fs xml:id="px2" type="prolex" n="- 155 124"> <f name="Alphabet"><symbol value="fr"/></f> <f name="Fréqtot"><numeric value="1"/></f> <f name="Longueur"><numeric value="1"/></f> <f name="Gramr"><symbol value="Dél"/></f> </fs> <fs xml:id="px3" type="prolex" n=". 154 49"> <f name="Alphabet"><symbol value="fr"/></f> <f name="Fréqtot"><numeric value="9"/></f> <f name="Longueur"><numeric value="1"/></f> <f name="Gramr"><symbol value="Pon"/></f> </fs> <fs xml:id="px4" type="prolex" n=": 156 39"> <f name="Alphabet"><symbol value="fr"/></f> <f name="Fréqtot"><numeric value="3"/></f> <f name="Longueur"><numeric value="1"/></f> <f name="Gramr"><symbol value="Pon"/></f> </fs> <fs xml:id="px5" type="prolex" n="; 157 27"> <f name="Alphabet"><symbol value="fr"/></f> <f name="Fréqtot"><numeric value="4"/></f> <f name="Longueur"><numeric value="1"/></f> <f name="Gramr"><symbol value="Pon"/></f> </fs> <fs xml:id="px6" type="prolex" n="a 1 129"> <f name="Alphabet"><symbol value="fr"/></f> <f name="Fréqtot"><numeric value="2"/></f> <f name="Longueur"><numeric value="1"/></f> <f name="Gramr"><coll org="set"><symbol value="Vaux"/><symbol value="Vconj"/></coll></f> </fs> <fs xml:id="px7" type="prolex" n="accrochant 3 18"> <f name="Alphabet"><symbol value="fr"/></f> <f name="Fréqtot"><numeric value="1"/></f> <f name="Longueur"><numeric value="10"/></f> <f name="Gramr"><coll org="set"><symbol value="Adjqua"/><symbol value="Vparpré"/></coll></f> </fs> <fs xml:id="px8" type="prolex" n="adieux 4 272"> <f name="Alphabet"><symbol value="fr"/></f> <f name="Fréqtot"><numeric value="1"/></f> <f name="Longueur"><numeric value="6"/></f> <f name="Gramr"><symbol value="Nomcom"/></f> </fs> <fs xml:id="px9" type="prolex" n="amants 5 173"> <f name="Alphabet"><symbol value="fr"/></f> <f name="Fréqtot"><numeric value="1"/></f> <f name="Longueur"><numeric value="6"/></f> <f name="Gramr"><symbol value="Nomcom"/></f> </fs> <fs xml:id="px10" type="prolex" n="ange 6 279"> <f name="Alphabet"><symbol value="fr"/></f> <f name="Fréqtot"><numeric value="1"/></f> <f name="Longueur"><numeric value="4"/></f> <f name="Gramr"><symbol value="Nomcom"/></f> </fs> <!-- etc... --> <fs xml:id="pw2" type="protex" n="le 27"> <f name="Édition"><symbol value="maj"/></f> <f name="champ"><symbol value="titre"/></f> </fs> <fs xml:id="pw3" type="protex" n="dormeur"> <f name="Édition"><symbol value="nil"/></f> <f name="champ"><symbol value="titre"/></f> </fs> <fs xml:id="pw4" type="protex" n="du"> <f name="Édition"><symbol value="nil"/></f> <f name="champ"><symbol value="titre"/></f> </fs> <fs xml:id="pw5" type="protex" n="val 39"> <f name="Édition"><symbol value="fdl"/></f> <f name="champ"><symbol value="titre"/></f> </fs> <fs xml:id="pw7" type="protex" n="c' 33"> <f name="Édition"><coll org="set"><symbol value="collé"/><symbol value="par"/><symbol value="cap"/></coll></f> <f name="champ"><symbol value="poème"/></f> </fs> <fs xml:id="pw8" type="protex" n="est 33"> <f name="Édition"><symbol value="nil"/></f> <f name="champ"><symbol value="poème"/></f> </fs> <fs xml:id="pw9" type="protex" n="un 33"> <f name="Édition"><symbol value="nil"/></f> <f name="champ"><symbol value="poème"/></f> </fs> <fs xml:id="pw10" type="protex" n="trou"> <f name="Édition"><symbol value="nil"/></f> <f name="champ"><symbol value="poème"/></f> </fs> <fs xml:id="pw11" type="protex" n="de 21"> <f name="Édition"><symbol value="nil"/></f> <f name="champ"><symbol value="poème"/></f> </fs> <fs xml:id="pw12" type="protex" n="verdure"> <f name="Édition"><symbol value="nil"/></f> <f name="champ"><symbol value="poème"/></f> </fs> <fs xml:id="pw13" type="protex" n="où 15"> <f name="Édition"><symbol value="nil"/></f> <f name="champ"><symbol value="poème"/></f> </fs> <fs xml:id="pw14" type="protex" n="chante"> <f name="Édition"><symbol value="nil"/></f> <f name="champ"><symbol value="poème"/></f> </fs> <fs xml:id="pw15" type="protex" n="une"> <f name="Édition"><symbol value="nil"/></f> <f name="champ"><symbol value="poème"/></f> </fs> <fs xml:id="pw16" type="protex" n="rivière"> <f name="Édition"><symbol value="fdl"/></f> <f name="champ"><symbol value="poème"/></f> </fs> <fs xml:id="pw18" type="protex" n="accrochant"> <f name="Édition"><symbol value="maj"/></f> <f name="champ"><symbol value="poème"/></f> </fs> <fs xml:id="pw19" type="protex" n="follement"> <f name="Édition"><symbol value="nil"/></f> <f name="champ"><symbol value="poème"/></f> </fs> <fs xml:id="pw20" type="protex" n="aux"> <f name="Édition"><symbol value="nil"/></f> <f name="champ"><symbol value="poème"/></f> </fs> <fs xml:id="pw21" type="protex" n="herbes"> <f name="Édition"><symbol value="nil"/></f> <f name="champ"><symbol value="poème"/></f> </fs> <fs xml:id="pw22" type="protex" n="des 150"> <f name="Édition"><symbol value="nil"/></f> <f name="champ"><symbol value="poème"/></f> </fs> <fs xml:id="pw23" type="protex" n="haillons"> <f name="Édition"><symbol value="fdl"/></f> <f name="champ"><symbol value="poème"/></f> </fs> <fs xml:id="pw25" type="protex" n="d' 155"> <f name="Édition"><coll org="set"><symbol value="collé"/><symbol value="cap"/></coll></f> <f name="champ"><symbol value="poème"/></f> </fs> <fs xml:id="pw26" type="protex" n="argent"> <f name="Édition"><symbol value="nil"/></f> <f name="champ"><symbol value="poème"/></f> </fs> <fs xml:id="pw27" type="protex" n="; 47"> <f name="Édition"><symbol value="nil"/></f> <f name="champ"><symbol value="poème"/></f> </fs> <!-- etc... --> </p> </body> </text> |
</TEI> |
Examinons les composantes de ce fichier.
<?xml ... C'est le prologue habituel.
<!DOCTYPE TEI ... C'est la définition du type de document indiquant ici qu'il s'agit d'un document TEI avec les modules iso-fs et linking pour les liens.
<teiHeader> ... C'est l'entête TEI. Les définitions de milestone sont disparues au profit de définitions de structures de traits contenues dans des fichiers externes. Par exemple, <fsdDecl type="prolex" url="poeme_fsd.xml"/> indique que la définition se trouve dans le fichier poeme_fsd.xml.
<body> ... C'est ici que se trouve les annotations. On a d'abord un <linkGrp type="prop" targFunc="token prolex protex"> qui contient une suite de <link targets="poemes.xml#w49 #px3 #pw49"> qui relient un mot (<w>) à une structure de traits lexicaux et à une structure de traits contextuels. Dans notre exemple, on lie le mot w49 contenu dans le fichier poemes.xml, la structure de traits lexicaux px3 et la structure de traits contextuels pw49.
Examinons une structure de traits.
Voici, finalement le contenu du fichier poeme_fsd.xml qui tient lieu de dictionnaire de données pour les structures de traits. L'existence de ce fichier n'est pas obligatoire, mais est fortement recommandée par le TEI. Si un tel dictionnaire est utile du point de vue documentaire, il est aussi très précieux pour le programme qui doit lire le fichier d'annotation et qui saura en partant à quoi il doit s'attendre...
| Exemple de fichier de déclarations de systèmes de traits |
|---|
<?xml version="1.0" encoding="iso-8859-1"?> |
<!DOCTYPE teiFsd2 SYSTEM "..\dtd\declarefs.dtd" [ <!ENTITY % TEI.XML "INCLUDE">] > |
<teifsd> |
<teiHeader> <fileDesc> <titleStmt> <title>Deux poèmes célèbres...</title> <author>... à compléter</author> </titleStmt> <publicationStmt> <p>Publié par...</p></publicationStmt> <sourceDesc> <p>Texte fourni par ... </p></sourceDesc> </fileDesc> </teiHeader> |
<fsDecl type="prolex"> <fsDescr>Définition des propriétés lexicales</fsDescr> <fDecl name="Alphabet" org="set"/> <fDescr></fDescr> <vRange> <symbol value="nil"/> <symbol value="fr"/> </vRange> <vDefault><symbol value="nil"/></vDefault> </fDescr> <fDecl name="Fréqtot" org="unit"/> <fDescr></fDescr> <vRange> <numeric value="0" max="65535" trunc="true"/> </vRange> <vDefault><numeric value="0"/></vDefault> </fDescr> <fDecl name="Longueur" org="unit"/> <fDescr></fDescr> <vRange> <numeric value="0" max="65535" trunc="true"/> </vRange> <vDefault><numeric value="0"/></vDefault> </fDescr> <fDecl name="Gramr" org="set"/> <fDescr></fDescr> <vRange> <symbol value="nil"/> <symbol value="Abr"/> <symbol value="Adjdém"/> <symbol value="Adjexc"/> <symbol value="Adjind"/> <symbol value="Adjint"/> <symbol value="Adjnum"/> <symbol value="Adjpos"/> <symbol value="Adjqua"/> <symbol value="Adjrel"/> <symbol value="Adv"/> <symbol value="Artdéf"/> <symbol value="Artind"/> <symbol value="Artpar"/> <symbol value="Con"/> <symbol value="Dél"/> <symbol value="Int"/> <symbol value="Mor"/> <symbol value="Nomcom"/> <symbol value="Nompro"/> <symbol value="Ono"/> <symbol value="Pon"/> <symbol value="Pré"/> <symbol value="Prodém"/> <symbol value="Proexc"/> <symbol value="Proind"/> <symbol value="Proint"/> <symbol value="Proper"/> <symbol value="Propos"/> <symbol value="Proréf"/> <symbol value="Prorel"/> <symbol value="Rés"/> <symbol value="X"/> <symbol value="Vaux"/> <symbol value="Vconj"/> <symbol value="Vinf"/> <symbol value="Vparpas"/> <symbol value="Vparpré"/> </vRange> <vDefault><symbol value="nil"/></vDefault> </fDescr> </fsDecl> <fsDecl type="protex"> <fsDescr>Définition des propriétés textuelles</fsDescr> <fDecl name="Édition" org="set"/> <fDescr></fDescr> <vRange> <symbol value="nil"/> <symbol value="collé"/> <symbol value="lié"/> <symbol value="maj"/> <symbol value="par"/> <symbol value="cap"/> <symbol value="tab"/> <symbol value="2"/> <symbol value="3"/> <symbol value="4"/> <symbol value="5"/> <symbol value="6"/> <symbol value="7"/> <symbol value="8"/> <symbol value="np"/> <symbol value="fdl"/> </vRange> <vDefault><symbol value="nil"/></vDefault> </fDescr> <fDecl name="champ" org="set"/> <fDescr></fDescr> <vRange> <symbol value="nil"/> <symbol value="titre"/> <symbol value="poème"/> <symbol value="signature"/> </vRange> <vDefault><symbol value="nil"/></vDefault> </fDescr> </fsDecl> |
</teifsd> |
Dans sa forme générale, ce fichier ressemble à une suite de structures de traits qui contiendrait toutes les valeurs admissibles de chacun des traits. Examinons les composantes du fichier.
<?xml ... C'est le prologue habituel.
<!DOCTYPE teifsd ... C'est la définition du type de document indiquant ici qu'il s'agit d'un document teifsd.
<teiHeader> ... C'est l'entête TEI dans une forme simplifiée.
<fsDecl ... Introduit les déclarations de structures de traits, une pour chacun des deux types : prolex et protex. On a ensuite la définition de chaque trait. La balise <vRange> introduit les valeurs posssibles tandis que <vDefault> permet de définir la valeur par défaut.
On aura remarqué que les fichiers XML sont très verbeux. Les structures, très redondantes, sont aussi très régulières, ce qui simplifie le traitement informatique. Comme les librairies de parsage sont disponibles dans les langages usuels, on peut y faire systématiquement appel en raison même de la régularité de la syntaxe. Au niveau du stockage des fichiers, les algorithmes de compression de type zip et autres permettent des niveaux de compression très élevés, ce qui permet de réduire la taille des fichiers à des fins de stockage et d'échange.
Les passerelles ont été programmées par François Daoust, Frédéric Doll et Gaelle Dobrowolski. La passerelle SATO vers TEI a été remplacée par un mode d'exportation natif permettant d'exploiter le découpage en mots et l'annotation déportée.
Les divers modules ont été regroupés en deux programmes:
Les passerelles peuvent être utilisées en mode autonome dans une console DOS par exemple. Comme elles sont écrites en Perl, elles peuvent être utilisées sous Unix, Linux et MacOS. Elles supportent aussi le protocole satox permettant la lecture d'un fichier de commandes, ce qui a permis de les implanter facilement sur le web.
À vous la parole...