| SATO 4.4, Manuel de référence (ajouté en aout 2012) |
| Table des matières | Définitions |
| Exercices pour l'apprentissage de SATO |
|
Ce chapitre contient une série d'exercices destinés à faciliter l'apprentissage de la syntaxe de commande de SATO. Ces exercices sont divisés en 9 sections. |
Introduction
Déclaration
|
Introduction
Ces exercices s'inspirent de la démonstration sur les fables de La
Fontaine. Il est donc conseillé de parcourir ces démonstrations avant
d'effectuer les exercices.
Pour entrer en analyse sur le corpus des deux fables de La Fontaine
- Ouvrir une session SATO avec l'application «SATO en mode intégral» : compléter le formulaire et cliquer sur «Appliquer»;
- Sur la page de Bienvenue, cliquer sur «Entrer»;
- Dans le menu (fenêtre de gauche), cliquer sur «Textes publics» sous l'onglet «Analyser»;
- Cliquer sur «Corpus littéraires»;
- Dans la fenêtre principale (fenêtre de droite) cliquez sur « Deux fables de la fontaine »;
- Vous êtes maintenant dans SATO en mode intégral caractérisé par une interface dans des tons orangers.
Chacun des exercices propose une tâche. En pointant la souris sur la réponse, on révèle la commande qui permet de réaliser la tâche et de repérer le formulaire de l'interface Web qui facilite l'écriture de la commande.
1. Le texte et ses propriétés
Le parcours du texte, en exploitant les propriétés textuelles
qui le structurent, est l'étape la plus intuitive de l'exploration d'un
texte.
Les exercices qui suivent visent une première
familiarisation avec la notion de filtre permettant de sélectionner des
parties du corpus en fonction de valeurs de propriétés.
Rappel : Dans le coin supérieur droit des formulaires de
commandes SATO, on trouve le lien vers la page pertinente du Manuel de
référence.
* 1.1 Affichez (décrire) l'information générale sur le texte
Réponse : Texte décrire
* 1.2 Affichez le texte au complet (utiliser le joker $ désignant une chaîne de caractères quelconque)
Réponse : Texte afficher $
* 1.3 Quelles sont les propriétés qui caractérisent la présentation du texte? Réponse : Texte caractériser présentation ?
* 1.4 Réduisez la liste de présentation du texte à la propriété locuteur
Réponse : Texte caractériser présentation = locuteur
* 1.5 Affichez les interventions de La Fontaine (toutes les chaînes de caractères pour lesquelles la valeur de la propriété «locuteur» est «lafont»)
Réponse : Texte afficher $*locuteur=lafont
* 1.6 Affichez les interventions du boeuf et de la grenouille (propriété «locuteur» avec un patron alternatif désignant les valeurs «boeuf» ou «grenouil»)
Réponse : Texte afficher $*locuteur=(boeuf,grenouil)
* 1.7 Affichez le document grenouil (toutes les chaînes de caractères pour lesquelles la propriété «page» est «grenouil»)
Réponse : Texte afficher $*page=grenouil
* 1.8 Rétablissez la liste de présentation du texte en choisissant les propriétés «page», «commentaire» et «locuteur»
Réponse : Texte caractériser présentation = page commentaire locuteur [Exploration
: si vous ne l'avez pas déjà fait, cliquez sur l'onglet «Journal» de la
section «Outils» du menu de gauche et découvrez la trace de vos
manipulations avec SATO.]
2. Le lexique et ses propriétés
L'accès
au lexique du corpus est un premier outil d'analyse qui permet de
saisir la thématique d'un discours et l'usage de divers marqueurs
linguistiques qui donnent des indices sur la position des locuteurs.
Les exercices qui suivent vont permettre d'approfondir la
compréhension de la syntaxe du filtre appliqué ici à la sélection des
formes lexicales.
* 2.1 Affichez (décrire) l'information générale sur le lexique. Réponse : Lexique décrire
* 2.2 Affichez la première page du lexique trié par ordre alphabétique (utiliser le joker $ désignant une chaîne de caractères quelconque)
Réponse : Lexique afficher $ tri alphabet [Exploration
: Cliquez sur un mot du lexique : visiter le menu de catégorisation
apparaissant au bas de l'écran et cliquez sur l'onglet KWIC pour
découvrir les contextes courts du mot.]
* 2.3 Ajoutez la propriété longueur à la liste de présentation
Réponse : Lexique caractériser présentation + longueur
* 2.4 Affichez par ordre de fréquence tous les mots dont la longueur (propriété «longueur») est supérieure à 1
Réponse : Lexique afficher $*longueur>1 tri fréqtot
* 2.5 Affichez par ordre alphabétique tous les mots qui se terminent par «en» (utiliser le joker désignant une chaîne de caractères quelconque suivi des caractères recherchés)
Réponse : Lexique afficher $en tri alphabet
* 2.6 Affichez tous les mots qui contiennent la séquence de caractères «en» triés par la longueur
Réponse : Lexique afficher $en$ tri longueur
* 2.7 Affichez tous les mots qui contiennent la séquence «en» et dont la fréquence totale est supérieure à 1 triés par la longueur (on peut utiliser la boîte de saisie de commande du journal, y copier la commande précédente et la compléter)
Réponse : Lexique afficher $en$*fréqtot>1 tri longueur
* 2.8 Enlevez la propriété longueur de la liste de présentation
Réponse : Lexique caractériser présentation - longueur
3. Les contextes
Le repérage de contextes permet des parcours ciblés du texte.
SATO permet non seulement de trouver les contextes d'utilisation d'un
mot, mais il permet aussi de construire des patrons de cooccurrences
pouvant comporter des contraintes sur la position relative des mots
entre eux. À la notion de filtre, permettant de sélectionner un ensemble
de mots pour une position, s'ajoute ici la notion de patron de
concordance permettant de combiner plusieurs filtres. On verra aussi
comment on peut modifier la taille et le type de contextes repérés.
* 3.1 Trouvez (appliquer) les contextes où apparaît le mot «maître»
Réponse : Contexte appliquer maître
* 3.2 Affichez tous les contextes trouvés (remarque $ est utilisé pour désigner tous les contextes)
Réponse : Contexte afficher $
* 3.3 Trouvez les contextes ou apparaissent les mots débutant par «gros» triés par ordre alphabétique (remarque : l'opérateur *@ force ce tri)
Réponse : Contexte appliquer gros$*@
* 3.4 Affichez les contextes trouvés
Réponse : Contexte afficher $
* 3.5 Trouvez les contextes où apparaissent à la fois les mots «boeuf» et «grenouille» (remarque : utiliser un patron de concordance composé de 2 filtres
Réponse : Contexte appliquer boeuf grenouille
* 3.6 Affichez les contextes trouvés
Réponse : Contexte afficher $
* 3.7 Caractériser les bornes des contextes comme étant des phrases délimitées par une ponctuation forte (remarque : pour faire la liste des ponctuations, on utilise un filtre qui définit une alternative)
Réponse : Contexte caractériser bornes = délimitées (.,?,!,:,;,...) exclu (.,?,!,:,;,...) inclus
* 3.8 Trouvez les contextes ou apparaît l'expression «un boeuf» (remarque
: l'opérateur de distance *. *.2 *.3 concaténé à un filtre indique la
distance maximale qui le sépare du mot suivant; *. est équivalent à *.1)
Réponse : Contexte appliquer un*. boeuf*.
* 3.9 Affichez les contextes trouvés
Réponse : Contexte afficher $
* 3.10 Trouvez les contextes où apparaît la
séquence «tout» «prince». Le mot «prince» doit suivre le mot tout à une
distance maximale de 2 : ex. «tout» «prince» (distance 1); «tout» xxx
«prince» (distance 2)
Réponse : Contexte appliquer tout*.2 prince*.
* 3.11 Affichez les contextes trouvés
Réponse : Contexte afficher $
4. Les propriétés
Le système des propriétés est un des dispositifs fondamentaux
de SATO. Cette section vise à se familiariser avec la manipulation des
propriétés : affichage de la définition d'une propriété, production de
statistiques descriptives sur son utilisation et création de propriétés
sans héritage. Les exercices vont permettre de créer les propriétés
«F1», «F2» et «Qualité» qui seront utilisées par la suite pour
reproduire les analyses présentées dans la démonstration sur les fables
de La Fontaine.
* 4.1 Afficher la définition de la propriété «Fréqtot»
Réponse : Propriété afficher Fréqtot
* 4.2 Afficher la définition de la propriété «Locuteur»
Réponse : Propriété afficher Locuteur
* 4.3 Produisez une statistique descriptive sur la distribution de toutes les valeurs de la propriété «Fréqtot»
Réponse : Propriété décrire Fréqtot pour $
* 4.4 Produisez une statistique descriptive sur la distribution des valeurs composées non «nil» de la propriété «Locuteur»
Réponse : Propriété décrire locuteur composé pour $*locuteur~nil
* 4.5 Définissez deux propriétés entières pour le lexique : «F1» et «F2»
Réponse : Propriété définir F1 entière pour lexique Propriété définir F2 entière pour lexique
* 4.6 Définissez la propriété «qualité» symbolique
pour le lexique Objectif : apprécier la portée de lexèmes
qualificatifs Valeurs : «négatif», «positif».
Réponse : Propriété définir qualité symbolique pour lexique négatif positif
5. La catégorisation lexicale manuelle
[ voir le tutoriel Catégorisation lexicale (pas-à-pas) ]
Le
menu de catégorisation, qui s'affiche lorsqu'on clique sur un mot
affiché dans la fenêtre centrale, permet d'annoter directement les
formes lexicales ou les mots en contexte. Les exercices qui suivent
permettront de réaliser une catégorisation des formes lexicales portant
un jugement positif ou négatif. On apprendra aussi comment définir des
clés (touches) supplémentaires ajoutant des raccourcis au menu de
catégorisation.
* 5.1 Catégorisation manuelle du lexique : lexèmes commençant par «b» catégorisation de «beau», «belle» «bon»
Réponse : Lexique afficher b$ tri alphabet
* 5.2 Définition de touches de catégorisation «n» pour «négatif»; «p» pour «positif»
Réponse : Poste
touche caractériser définition n = valeur qualité = négatif Poste
touche caractériser définition p = valeur qualité = positif
* 5.3 Catégorisation du lexique en utilisant les
touches programmées pour les mots «chétive», «confus», «envieuse»,
«honteux», «joli», «large», «phénix»
Réponse : Lexique afficher $ tri alphabet Cliquez sur les mots à catégoriser
* 5.4 Description de la propriété «qualité» en mode composé
Réponse : Propriété décrire qualité composé pour $
* 5.5 Coloration des lexèmes selon leur qualité : «color: red» pour «négatif» et «color: green» pour «positif» (utiliser
l'onglet «Poste/Écran» dans le menu pour caractériser la couleur de
telle sorte que les mots soient colorés en fonction des valeurs de la
propriété «qualité» On peut caractériser la couleur de chaque valeur de
propriété.)
Réponse : Poste
écran caractériser couleur = qualité Propriété caractériser qualité
couleur négatif = color: red; Propriété caractériser qualité couleur
positif = color: green;
* 5.6 Affichage des lexèmes qualifiés par ordre alphabétique
Réponse : Lexique Afficher $*qualité~nil tri alphabet
* 5.7 Affichage du document «corbeau»
Réponse : Texte afficher $*page=corbeau
6. Les dictionnaires
Les dictionnaires permettent de conserver des annotations
lexicales qui pourront être appliquées sur des corpus possédant des
propriétés compatibles avec les entrées du dictionnaire. Il existe
plusieurs formats de dictionnaires. Dans ces exercices, nous allons
découvrir les dictionnaires séquentiels qui ne gèrent qu'un seul système
de catégories, contrairement aux dictionnaires indexés plus complexes
qui gèrent plusieurs champs.
* 6.1 Constitution d'un dictionnaire séquentiel avec la propriété «qualité» pour les mots catégorisés (remarque : les mots non catégorisés ont la valeur de propriété nil; les mots qui ont reçu une valeur pour qualité sont ~ nil)
Réponse : Dictionnaire séquentiel attribuer qualite propriété qualité pour $*qualité~nil
* 6.2 Affichage du dictionnaire «qualite» avec sa définition
Réponse : Dictionnaire séquentiel afficher qualite $ Définition
* 6.3 Attribution de la valeur «nil» à la propriété «qualité» tous les lexèmes qualifiés
Réponse : Propriété attribuer qualité = valeur nil pour $*qualité~nil
* 6.4 Application du dictionnaire séquentiel «qualite.dic» sur la propriété «qualité»
Réponse : Dictionnaire séquentiel appliquer qualite propriété qualité pour $
* 6.5 Affichage par ordre alphabétique des lexèmes qualifiés
Réponse : Lexique Afficher $*qualité~nil tri alphabet
7. Définition de sous-textes
La constitution de sous-textes est le mécanisme qui permet de
calculer les fréquences associées à diverses parties du texte. Un
sous-texte peut résulter du répérage de contextes (concordances). Il
peut aussi être le résultat de l'application d'un filtre permettant de
choisir des mots en fonction de leurs valeurs de propriétés (page,
locuteur, etc...). C'est ce que nous allons faire dans cette section,
l'objectif étant de comparer la première et la seconde fable, comme
illustré dans la démonstration sur les fables de La Fontaine. Pour ce
faire, on utilisera les propriétés entières «F1» et «F2» définies dans
la section «Propriétés».
* 7.1 Définition du sous-texte
«CORBEAU» et conservation du lexique associé dans la propriété «F1». Le
sous-texte est décrit par un filtre désignant l'ensemble des mots du
document «corbeau».
Réponse : Texte caractériser sous-texte = filtre $*page=corbeau CORBEAU lexique F1
* 7.2 Définition du sous-texte «GRENOUILLE» et
conservation du lexique associé dans la propriété «F2». Le sous-texte
est décrit par un filtre désignant l'ensemble des mots du document
«grenouil».
Réponse : Texte caractériser sous-texte = filtre $*page=grenouil GRENOUILLE lexique F2
* 7.3 Rappel du sous-texte «CORBEAU» * Afficher le texte pour vérifier
Réponse : Texte caractériser sous-texte = rappel CORBEAU Texte afficher $
* 7.4 Retour au texte principal
Réponse : Texte caractériser sous-texte = tout
8. Les analyseurs Distance et Participation
Suite aux travaux précédents, nous avons l'information pour
appliquer des analyseurs lexicométriques sur les propriétés entières qui
résument des sections caractéristiques du corpus.
L'analyseur DISTANCE calcule les différences d'utilisation
des formes (ou des catégories) lexicales entre deux sous-textes. Pour ce
faire, il fait appel aux propriétés entières pour le lexique qui
cumulent les fréquences d'utilisation du vocabulaire dans chacun des
sous-texte. Ces propriétés correspondent en fait à des vecteurs qui
situent les sous-textes correspondant dans l'espace lexical. On peut
donc calculer la distance entre points textes dans l'espace lexical.
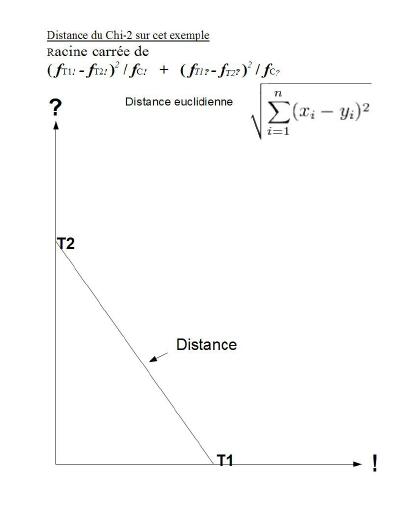 |
fT1! fréquence de ! dans le sous-texte 1 (corbeau)
fT2! fréquence de ! dans le sous-texte 2 (grenouil)
fC! fréquence de ! dans le corpus
fT1? fréquence de ? dans le sous-texte 1 (corbeau)
fT2? fréquence de ? dans le sous-texte 2 (grenouil)
fC? fréquence de ? dans le corpus
|
* 8.1
Considérant que les propriétés «F1» et «F2» représentent le lexique
des fables 1 (CORBEAU) et 2 (GRENOUILLE), calculez la distance entre
«F1» et »F2» pour tous les mots dont la fréquence totale est supérieure à
1
Commande : Analyseur Distance afficher F1 F2 $*fréqtot>1
Résultat :
Analyseur Distance afficher F1 F2 $*fréqtot>1
distance: 10.32
Nombre de dimensions: 59
distance/dimension: 0.175
Liste des unités contribuant le plus à la distance:
*
Fréqtot F1 F2 explique cumul
1.260 0.000 2.700 5.450 5.450 ?
0.943 0.000 2.030 4.090 9.540 -
0.943 0.000 2.030 4.090 13.600 n'
0.943 0.000 2.030 4.090 17.700 point
0.943 0.000 2.030 4.090 21.800 veut
1.890 0.588 3.380 3.870 25.700 tout
7.550 10.000 4.730 3.450 29.100 , *
0.943 1.760 0.000 3.100 32.200 ! *
0.943 1.760 0.000 3.100 35.300 corbeau *
0.943 1.760 0.000 3.100 38.400 à *
0.629 0.000 1.350 2.720 41.100 boeuf
0.629 0.000 1.350 2.720 43.900 comme
0.629 0.000 1.350 2.720 46.600 elle
0.629 0.000 1.350 2.720 49.300 est
0.629 0.000 1.350 2.720 52.000 grenouille
0.629 0.000 1.350 2.720 54.800 grosse
0.629 0.000 1.350 2.720 57.500 la
1.570 0.588 2.700 2.670 62.900 qui
0.629 1.180 0.000 2.060 64.900 \Corbeau *
0.629 1.180 0.000 2.060 67.000 \Monsieur *
0.629 1.180 0.000 2.060 69.100 bec *
0.629 1.180 0.000 2.060 71.100 ces *
0.629 1.180 0.000 2.060 73.200 fromage *
0.629 1.180 0.000 2.060 75.300 maître *
0.629 1.180 0.000 2.060 77.300 peu *
0.629 1.180 0.000 2.060 79.400 renard *
0.629 1.180 0.000 2.060 81.500 sa *
0.629 1.180 0.000 2.060 83.500 sans *
0.629 1.180 0.000 2.060 85.600 votre *
0.629 1.180 0.000 2.060 87.700 êtes *
2.520 3.530 1.350 1.770 89.400 le *
1.260 0.588 2.030 1.540 91.000 s'
1.260 0.588 2.030 1.540 92.500 y
2.200 2.940 1.350 1.080 93.600 un *
1.260 1.760 0.676 0.885 95.400 que *
1.260 1.760 0.676 0.885 96.200 vous *
0.943 0.588 1.350 0.579 96.800 bien
0.943 0.588 1.350 0.579 97.400 des
0.943 0.588 1.350 0.579 98.000 pas
1.890 2.350 1.350 0.499 98.500 " *
1.890 2.350 1.350 0.499 99.000 et *
1.570 1.180 2.030 0.432 99.400 en
0.943 1.180 0.676 0.249 99.700 ne *
1.570 1.760 1.350 0.102 99.800 de *
3.770 3.530 4.050 0.068 99.800 .
1.890 1.760 2.030 0.034 99.900 :
1.260 1.180 1.350 0.023 99.900 se
0.629 0.588 0.676 0.011 99.900 ;
0.629 0.588 0.676 0.011 99.900 belle
0.629 0.588 0.676 0.011 99.900 ce
0.629 0.588 0.676 0.011 99.900 du
0.629 0.588 0.676 0.011 99.900 lui
0.629 0.588 0.676 0.011 100.000 plus
0.629 0.588 0.676 0.011 100.000 pour
0.629 0.588 0.676 0.011 100.000 qu'
0.629 0.588 0.676 0.011 100.000 si
0.629 0.588 0.676 0.011 100.000 vit
* 8.2
L'analyseur PARTICIPATION prend en compte un ensemble donné
du vocabulaire (par exemple les marqueurs du style interrogatif, les
mots portant une catégorie spécifique, etc.) et donne des indices de
son utilisation dans un ensemble de sous-textes. La cote Z est
une mesure normalisée de l'écart entre la fréquence observée dans un
sous-texte et la fréquence calculée sur l'ensemble du corpus. Cette
fréquence dans le corpus d'un ensemble donnée de mots est considérée
comme la moyenne d'une loi de distribution normale. L'hypothèse nulle
est que le sous-texte est un échantillon aléatoire tiré du corpus.
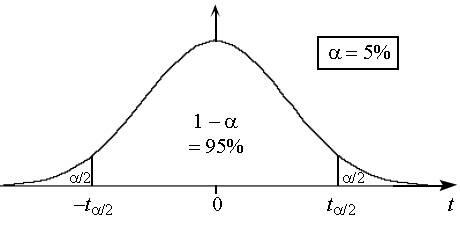
La cote Z correspond à l'écart-type calculé sur la base
d'une distribution normale centrée et réduite. Selon cette
distribution, la valeur de la cote Z d'échantillons aléatoires
tirés du corpus se situe à l'intérieur d'un intervalle de 2
écarts-types 95 fois sur 100. Donc, plus la valeur de l'écart-type
s'éloigne de 2 (1,96), en plus (sur-représentation) ou en moins
(sous-représention), plus on est autorisé à rejeter l'hypothèse nulle
pour conclure que la fréquence du vocabulaire dans le sous-texte
s'écarte significativement de la fréquence dans le corpus.
Considérant que le point d'interrogation et le trait d'union sont
utilisés dans les fables comme des indices de la forme interrogative,
utilisez l'analyseur PARTICIPATION pour vérifier que leur utilisation
diffère de façon significative. Indice...utilisez le filtre (?,-)
Réponse : Analyseur participation appliquer (?,-) F1 F2 Fréqtot

Commande : Analyseur participation appliquer (?,-) F1 F2 Fréqtot
Résultat :
ANALYSEUR PARTICIPATION APPLIQUER (?,-) F1 F2
Propriété
|
Couverture
|
Lexèmes
|
Occurrences
|
Cote Z
|
F1
|
170/318
53.46%
|
0/103
0.00%
|
0/170
0.00%
|
-1.96
|
|
|
|
|
|
F2
|
148/318
46.54%
|
2/94
2.13%
|
7/148
4.73%
|
2.10 |
9. Les scénarios
Les scénarios sont des fichiers qui contiennent des suites de
commandes SATO. Généralement, on les constitue à partir d'un
«copier-coller» du journal. Dans cet exercice, on définira le scénario
«distfab» en repiquant à partir du journal les commandes qui permettent
de reproduire l'analyse de distance et de participation réalisée au
cours des travaux pratiques.
* 9.1 Édition du journal pour composer le scénario
distfab.csa - Rafraîchir la fenêtre du bas qui contient le journal de
la session. - Définir un scénario dans SATO; Pour remplir la case de
saisie du scénario, il s'agit de copier/coller les commandes du journal
vers la boîte de saisie.
Réponse : Scénario définir distfab Contenu du scénario...
* Scénario qui reproduit le calcul de DISTANCE et PARTICIPATION
* sur deux fables de La Fontaine
PROPRIÉTÉ DÉFINIR F1 entière pour lexique
PROPRIÉTÉ DÉFINIR F2 entière pour lexique
TEXTE CARACTÉRISER SOUS-TEXTE = FILTRE $*page=corbeau CORBEAU lexique F1
TEXTE CARACTÉRISER SOUS-TEXTE = FILTRE $*page=grenouil GRENOUILLE lexique F2
ANALYSEUR DISTANCE APPLIQUER f1 f2 $*fréqtot>1
ANALYSEUR PARTICIPATION APPLIQUER (?,-) F1 F2 Fréqtot
Dans la fenêtre de saisie du scénario, effacer toutes les commandes qui
ne sont pas utiles pour calculer la distance. Garder la création des
propriétés F1 et F2, ainsi que la définition des sous-textes. Garder les
appels aux analyseurs DISTANCE et PARTICIPATION.
* 9.2 Caractérisation du scénario pour avoir, lors
de l'application du scénario, la journalisation des commandes qu'il
contient. Cela permettra de le valider
Réponse : Scénario caractériser journalisation = oui
* 9.3 Caractérisation du scénario pour avoir un
défilement normal afin de voir les résultats des commandes comme si
elles avaient été tapées au clavier (par défaut, on est en mode partiel
qui n'affiche pas les résultats des commandes «de service»).
Réponse : Scénario caractériser défilement = normal
* 9.4 Exécution du scénario distfab
Réponse : Scénario appliquer distfab