Illustration 1. Interface expert de SATO 4.3
| SATO 4.4, Manuel de référence (mars 2007) | |
| Table des matières | Définitions | |
| Présentation du logiciel SATO | |
|---|---|
| Le logiciel SATO est un outil informatique que l'on pourrait qualifier de tableur textuel en ce qu'il permet, comme un tableur le ferait pour des données numériques, de bâtir un plan d'analyse. Ainsi, le lecteur analyste peut se construire des procédures pour découvrir et exposer les procédés discursifs mis en oeuvre dans un ensemble de documents rassemblés dans un corpus mono ou multilingue. Les principales fonctions que permet SATO sont la génération de lexiques, la catégorisation et l'annotation de mots en contexte et hors contexte, la mise en forme et le stockage de données lexicales, la production d'analyses lexico-statistiques, la construction de dictionnaires, l'identification et la comparaison de segments et de sous-ensembles textuels constitués à la volée selon une variété de critères. | |
SATO est un «système d'analyse de textes par ordinateur» utilisé sur des plateformes informatiques de type IBM-PC et compatibles. Ce système est dédié à l'analyse du contenu des documents conservés sur support informatique.
Avec l'utilisation de SATO, la notion d'analyse textuelle recouvre une variété de significations. En voici quelques exemples.
En fait, toutes ces applications ont en commun trois caractéristiques :
Ceci nécessite de disposer d'un outil qui permette un accès rapide aux données et qui donne la liberté de considérer le texte en format intégral augmenté, si besoin, de divers niveaux de description. SATO est précisément développé pour satisfaire ce type de besoin.
En résumé, SATO est un système destiné à soutenir une variété d'activités d'analyse de données textuelles. Il permet l'annotation de documents qui peuvent être écrits en plusieurs langues, le repérage «sur mesure» des éléments du texte et l'analyse qualitative ou quantitative du document ou de ses parties. Pour ce faire, SATO offre les possibilités suivantes (pour ne nommer que les plus importantes) :
Le logiciel SATO est écrit en Delphi-PASCAL pour la plateforme Windows avec processeur Intel-Pentium et compatibles. Il utilise une architecture WEB qui peut être déployée sur un ordinateur personnel ou sur un serveur accessible par intranet ou internet. L'installation de SATO requiert aussi l'installation de logiciels tiers disponibles gratuitement, en particulier un interpréteur de scripts Perl et un serveur Web. Le logiciel SATO est distribué par le Centre d'analyse de textes par ordinateur (ATO) de l'Université du Québec à Montréal. ATO est un centre d'expertise et de consultation qui se consacre à l'analyse des textes au moyen de l'ordinateur.
Si, d'un point de vue matériel, le texte se donne d'abord comme une suite de caractères, du point de vue du lecteur, le texte se présente d'emblée comme une suite de «mots qui font sens». Pourquoi ces mots font-ils sens? D'abord parce qu'ils sont perçus comme des unités, c'est-à-dire des séquences de caractères délimitées explicitement ou reconnues implicitement par le lecteur comme des unités lexicales appartenant à une langue et référant à un monde réel ou imaginaire dont on peut se faire une représentation.
Donc, au-delà de sa définition purement matérielle en tant que feuille de papier imprimée ou page électronique, le texte met en oeuvre une dimension implicite, la dimension lexicale, et une dimension explicite qui correspond à l'ordre séquentiel de la lecture.
En conséquence, SATO situe le texte dans un espace, un plan composé de deux axes. On a d'abord un axe lexical qui dresse la liste du vocabulaire utilisé dans le texte. Ce vocabulaire (les formes lexicales) a un sens dans l'univers de la langue et du discours dans lequel s'inscrit le texte. Le deuxième axe représente la linéarité du texte qui se donne comme une suite d'occurrences des formes lexicales. De façon formelle, on peut donc voir un texte donné comme un série de points tracés sur ce plan.
Représentation d'un texte dans le plan lexique/occurrence
|
Représentation linéaire : je pense donc je suis
Un même lexique... deux textes
|
Représentation linéaire : je suis donc je pense
Cette représentation du texte dans sa double dimension, lexicale et séquentielle (voir la définition Lexème et occurrence ), est un choix fondamental qui va dicter le modèle informatique de SATO et le type d'opérations logiques mises en oeuvre dans les stratégies d'analyse de texte supportées par le système. Avant d'invoquer les fonctions d'analyse de SATO, on doit donc soumettre le corpus en format texte afin que SATO transforme le corpus de textes de sa représentation en chaînes de caractères à sa représentation logique en termes d'occurrences de formes lexicales dans leur contexte d'apparition dans l'ordre séquentiel du texte.
Destiné à soutenir des activités d'analyse, SATO offre la possibilité d'annoter le texte. Le travail d'annotation sur le texte est cette opération matérielle qui permet de marquer par un symbole le dépistage d'une unité cognitive.
Cette unité cognitive peut s'établir sur l'axe lexical. Par exemple, on peut reconnaître que tel lexème appartient à un vocabulaire familier pour un domaine de connaissances. On peut constater qu'il s'agit d'un adverbe, d'un marqueur d'argumentation, etc. L'unité dépistée peut également se définir sur le plan textuel (occurrence). Par exemple, le lexème le qui précède le mot lexème agit ici comme article.
Dans SATO, on utilise le terme propriété pour désigner un système catégoriel permettant de marquer des lexèmes ou des occurrences (voir la définition Mots et propriétés). Par exemple, une propriété connu et ses valeurs oui, p6, etc. pourrait servir à identifier les lexèmes connus de tous (comme les nombres), et ceux connus par les élèves de sixième année du primaire dans le système québécois d'éducation. Une propriété syntaxe pourrait permettre d'identifier la fonction grammaticale précise de l'occurrence d'un lexème alors que la propriété gramr pourrait servir à définir l'ensemble des fonctions grammaticales possibles du lexème.
En recoupant les systèmes catégoriels des propriétés avec la représentation du texte en deux dimensions, on obtient donc le modèle suivant.
Texte augmenté de propriétés
|
Représentation linéaire :
*partie=prém Je pense *partie=conn DONC *partie=conc je suis
Dans cet exemple, nous avons défini sur l'axe lexical deux propriétés ou fonctions catégorielles.
La propriété fréqtot est une propriété entière, ce qui signifie qu'elle prend comme valeur des nombre entiers positifs ou zéro. Cette propriété contient le nombre total d'occurrences du lexème dans le corpus de textes.
La propriété gramr est une propriété symbolique dont les valeurs possibles sont des symboles qui désignent des catégories grammaticales. La propriété fréqtot est une propriété prédéfinie de SATO alors que gramr est une propriété ajoutée.
Sur l'axe textuel, nous avons deux propriétés.
La propriété édition est une propriété prédéfinie de SATO dont les valeurs sont des symboles qui définissent des attributs de mise en page de l'occurrence. Par exemple, le symbole maj indique que la première occurrence du lexème je débute par un J majuscule.
La propriété partie est une propriété symbolique définie par l'analyste pour classer des occurrences d'après leur fonction argumentaire : prémisse, connecteur logique, conclusion.
Une fois soumis à SATO, le corpus, mis en forme dans le plan lexique/occurrences, pourra être interrogé et annoté dynamiquement. SATO se présente alors comme un outil de dialogue interactif conçu comme poste de travail du lecteur-analyste.
Rapportées sur le plan lexique/occurrences de SATO, les opérations que permet d'effectuer le logiciel se distribuent selon le schéma suivant.
Opérations sur le plan lexique/occurrence
|
On remarquera que certaines opérations sont disponibles tant sur l'axe du lexique que sur celui des occurrences.
Il s'agit en particulier des opérations d'affichage et d'exportation, qui sont aussi des opérations de sélection par l'utilisation du mécanisme des patrons de fouille, appelé aussi filtre. Le système SATO, en effet, utilise un langage de commandes dont la syntaxe permet de décrire avec beaucoup de flexibilité les objets primitifs du texte. Les patrons de fouille permettent de désigner des lexèmes ou des occurrences par la concaténation de filtres portant sur leurs caractères ou sur leurs valeurs de propriété.
Le filtre admet, comme élément de recherche, soit l'expression littérale des caractères ou soit une combinaison de caractères simples et de caractères spéciaux permettant notamment des jeux de troncation des parties gauche ou droite des chaînes de caractères. Par exemple, le filtre chargé dépistera la chaîne chargé alors que le filtre $ent dépistera tous les mots qui se terminent par ent comme parlent, comment, etc. Il faut remarquer que la syntaxe s'applique autant aux mots du texte qu'aux entrées du lexique ou aux valeurs de propriétés. Ainsi, le filtre $ent*domaine=bio-physique*fréq>34 dépistera les chaînes se terminant par ent, dont la propriété domaine a pour valeur bio-physique et dont la fréquence dans le corpus est plus grande que 34.
Cette syntaxe de description des mots, combinée à une structure de commandes également très générale, donne à SATO une grande souplesse. C'est ainsi que l'on dispose d'une base solide pour implanter des analyseurs et assurer une communication efficace entre l'utilisateur et le texte informatisé.
Le deuxième ensemble d'opérations, disponible sur les deux axes de notre plan, concerne la définition et l'exploitation des systèmes de propriétés.
On peut définir ou supprimer une propriété. Une des modalités intéressantes de l'opération de définition est l'héritage. Par exemple, si l'on a défini une propriété gramr sur le lexique, on peut définir une propriété syntaxe sur le texte qui «hérite», au moment de sa création, des valeurs de la propriété gramr. Il s'agit de propriétés distinctes qui pourront par la suite être modifiées de façon distincte. En particulier, on pourra modifier syntaxe pour chacune des occurrences du lexème afin de préciser en contexte la fonction grammaticale précise du mot.
Une autre opération commune aux systèmes des propriétés est l'attribution de valeurs. Cette opération se réalise par manipulation directe : on pointe l'objet (forme lexicale ou occurrence) avec la souris et on assigne des valeurs à l'une ou l'autre de ses propriétés. On peut aussi utiliser une commande d'affectation qui permet d'attribuer des valeurs à un ensemble de lexèmes ou d'occurrences décrits par un filtre. On pourra utiliser le mécanisme des concordances sur l'axe textuel pour catégoriser des occurrences en fonction de leur position en contexte.
On peut aussi décrire une propriété. Cette opération fait appel aux techniques de la statistique descriptive et permet de dresser un portrait de l'utilisation des valeurs de la propriété.
Finalement, on peut caractériser une propriété, c'est-à-dire définir ses attributs d'affichage : nombre de colonnes pour afficher la propriété, sa couleur, etc.
La caractérisation est aussi possible directement au niveau du lexique et des occurrences. Ainsi, on peut caractériser la présentation du lexique pour déterminer les propriétés que l'on veut visualiser. Il est en de même des propriétés textuelles dans le cas de l'affichage ou de l'exportation du texte. On peut aussi colorer le texte pour mettre en évidence les parties du texte correspondant aux diverses valeurs de propriété associées aux occurrences. En fait, SATO permet de modifier librement un très grand nombre de paramètres de visualisation.
Un type d'opérations spécifiques à l'axe lexical concerne la manipulation de dictionnaires. Pour SATO, un dictionnaire est un fichier externe, une base de données, qui permet d'associer des valeurs de propriété à des chaînes de caractères qui représentent normalement des formes lexicales. SATO fournit un ensemble de dispositifs pour créer, consulter et modifier des dictionnaires. On peut aussi les fouiller au moyen de filtres comme on le fait pour le lexique et le texte.
Finalement, SATO fournit des analyseurs lexicométriques. L'analyseur DISTANCE permet de repérer la différence d'utilisation du vocabulaire entre deux parties du corpus (appelés sous-textes dans SATO). Cette mesure est basée sur la distance du Chi2 appliquée aux fréquences lexicales relatives calculées pour chacun des deux sous-textes comparés. DISTANCE permet aussi d'indiquer quels sont les formes lexicales, ou les valeurs de propriété de ces formes, qui contribuent le plus à la distance entre les deux sous-textes dans l'espace lexical.
L'analyseur PARTICIPATION est le complément de DISTANCE. Il permet de calculer la proportion relative d'un ensemble de mots dans les divers sous-textes du corpus. On utilise la cote Z (écart-moyen centré et réduit) pour évaluer la signification statistique de l'écart fréquence entre le sous-texte et l'ensemble du corpus. Par exemple, dans un corpus d'entrevue, si la mesure de distance indique que le pronom je distingue les répondants masculins des répondants féminins, on pourra se servir de PARTICIPATION pour mesurer la portée statistique de l'utilisation différenciée des pronoms associés à la première personne (je me moi...) dans les divers sous-textes définis : répondants féminins, masculins, âgés, jeunes, etc.
La première opération qui concerne spécifiquement l'axe des occurrences a trait au repérage de segments textuels, c'est-à-dire des portions de texte possédant diverses caractéristiques. C'est le cas en particulier de la concordance (commande CONTEXTE APPLIQUER) qui permet de repérer des passages qui contiennent un ou plusieurs mots avec divers types de contraintes de cooccurrence ou de position dans la séquences des mots. On peut aussi se servir de la concordance pour réaliser une catégorisation automatique des mots repérés. Bien sûr, on pourra afficher ou exporter les passages repérés, en soulignant les mots dépistés en position de contrainte. Cette édition des contextes est accompagnée de références de pagination aussi précises que l'on désire.
Outre les concordances, il existe en SATO un deuxième mécanisme de repérage de contextes. Il s'agit de l'analyseur SEGMENTATION qui a pour fonction de partitionner le texte en segments. Par exemple, on pourrait découper le texte en documents, en paragraphes, en phrases possédant une certaine longueur, ou en segments de longueur fixe. On peut afficher ou exporter un ou plusieurs des segments ainsi repérés.
En faisant appel aux filtres ou au repérage de segments et contextes, on peut définir un sous-texte. Le sous-texte est une restriction sur l'axe des occurrences de SATO. La commande permet aussi de dresser le lexique du sous-texte.
Finalement, on dispose dans SATO d'analyseurs qui concernent directement l'axe des occurrences. Il s'agit en particulier de COMPARAISON, COMPTAGE, LISIBILITÉ, PARTICIPATION et TAMISAGE.
En fait, il faut signaler que SATO fournit peu d'analyseurs prédéfinis. SATO fournit surtout des fonctions et des opérations dont la combinaison permet à l'utilisateur de construire ses propres analyseurs. Ceux-ci vont prendre la forme de scénarios que l'on fait exécuter. Certains ont d'ailleurs comparé SATO à un «tableur textuel». Le tableur, ou feuille de calcul électronique, est ce type de logiciel qui permet à l'utilisateur de définir diverses fonctions de calcul associées à une matrice de données. Évidemment, les données textuelles et les fonctions de calcul disponibles en SATO ne sont pas celles du tableur mais la métaphore indique que SATO est, comme le tableur, un outil permettant de développer des applications d'analyse.
Sur le plan lexique/occurrences de la représentation SATO, nous avons placé le scénario à la jonction des deux axes. En effet, le plus souvent, les scénarios déploient des stratégies faisant appel à la combinaison de fonctions qui agissent sur l'un ou l'autre des deux axes.
Les scénarios prennent la forme de fichiers en format texte composés de séquences de commandes SATO. Ils sont, le plus souvent, composés à partir d'extraits du journal qui enregistre automatiquement toutes les opérations effectuées grâce à SATO. Une fois que l'on a mis au point des stratégies d'analyse en mode interactif, on reprend ces stratégies et on en fait des analyseurs.
Ceci nous amène à présenter l'ergonomie générale de SATO ou, en d'autres mots, le cadre de travail permettant d'opérer sur le plan lexique/occurrences en y appliquant les diverses fonctions déjà décrites.
L'environnement de travail avec le logiciel SATO repose sur trois dispositifs qui interagissent.
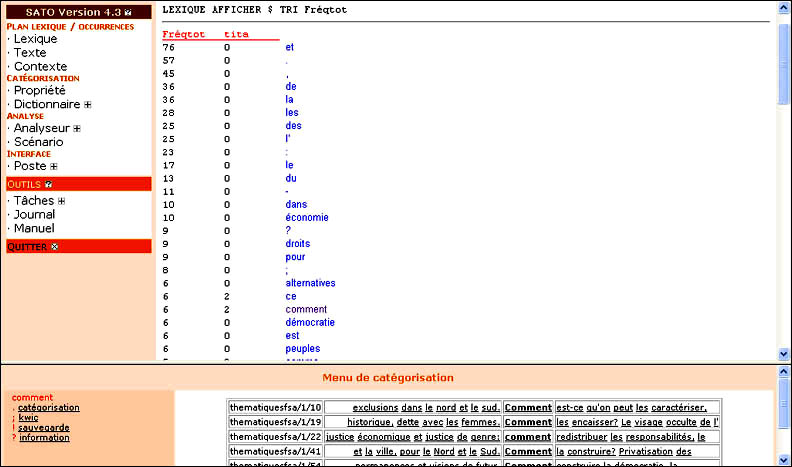
Il y a d'abord une interface interactive qui utilise des formulaires HTML pour guider l'usager dans l'élaboration de ses commandes. Les pages HTML contiennent des liens vers les sections pertinentes du Manuel de référence. Aussi, les formes lexicales et les occurrences affichées à l'écran suite à l'exécution d'une commande SATO seront des hyperliens donnant accès à un menu de catégorisation. Voici un bref descriptif des items du menu de catégorisation.
| . catégorisation | Pour ajouter (+), enlever (-) ou remplacer (=) une valeur de propriété pour le mot pointé; |
| ; kwic | Pour afficher les contextes courts (key word in contexte) pour le mot pointé; |
| ! sauvegarde | Pour sauvegarder les modifications aux propriétés; |
| [ bloc-début | Pour marquer l'occurrence pointée comme début d'un bloc de mots; |
| ] bloc-fin | Pour marquer l'occurrence pointée comme fin d'un bloc de mots; |
| : bloc-catégorisation | Pour marquer ajouter (+), enlever (-) ou remplacer (=) une valeur de propriété pour l'ensemble des mots du bloc courant; |
| * bloc-extrait | Pour extraire le bloc courant et lui donner un numéro; |
| ? information | Pour afficher l'information connue par SATO sur l'item pointé; |
| = ... | Applique la dernière catégorisation sur l'item pointé; |
| X | X représente ici une touche quelconque définie par l'usager (cf. POSTE TOUCHE). Ces touches permettent de définir des raccourcis pour la catégorisation manuelle. |
Le deuxième dispositif de l'interface SATO est le langage de commandes qui fait en sorte que toute manipulation interactive produit une commande explicite que l'on pourra insérer à l'intérieur de fichiers de commandes constituant des scénarios. C'est ainsi qu'un utilisateur expérimenté pourra développer des environnements de travail taillés sur mesure et des protocoles d'analyse réutilisables.

Le troisième dispositif caractérisant l'ergonomie de SATO est la production automatique d'un journal dressant un historique complet des interventions sur le corpus. Ce journal vise plusieurs objectifs. D'abord, il fournit un contexte élargi permettant à l'utilisateur d'avoir une mémoire de sa démarche exploratoire. Ensuite, le journal fournit un dispositif de sécurité permettant de reprendre des opérations ou de les corriger le cas échéant. Finalement, l'examen du journal permet un retour critique sur une démarche analytique effectuée dans les conditions plus spontanées de la phase exploratoire. C'est souvent à partir de l'examen du journal que l'on composera les scénarios qui vont permettre de cristalliser les stratégies de recherche les plus productives. Le scénario est donc issu généralement d'opérations de repiquage (couper-coller) à partir du journal.
Les scénarios de commandes ont donc un double statut. D'un point de vue technique d'abord, ce sont des programmes permettant de reproduire des stratégies d'analyse et de les appliquer dans un cadre de production. Mais ce sont aussi des objets scientifiques qui sont la matérialisation d'un savoir descriptif ou analytique.

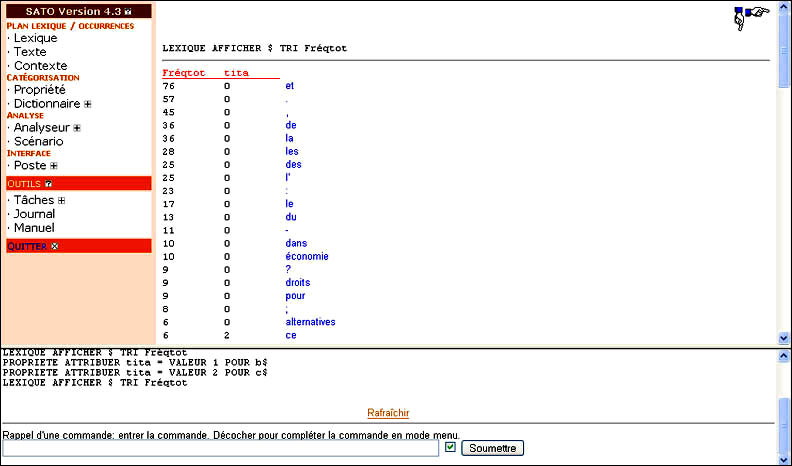
Visuellement, l'écran SATO se présente sous la forme d'une page HTML divisée en trois fenêtres. La fenêtre de gauche est le menu des commandes (voir point 1 de l'illustration ci-dessus). Un onglet suivi d'un signe + indique qu'il s'agit d'un titre de rubrique dont les sous-items seront dévoilés par un clic de la souris. L'onglet sera alors suivi du signe - indiquant que le sous-menu peut être refermé par un clic de la souris. La fenêtre centrale est utilisée pour afficher les formulaires de requêtes et les résultats des commandes (voir point 2 de l'illustration ci-dessus). Enfin, la fenêtre inférieure servira à diverses fins : affichage des chapitres du Manuel et des bulles d'aide, journal des commandes de la session courante et menu de catégorisation activé par un clic de la souris sur un mot du texte ou une entrée lexicale (voir point 3 de l'illustration ci-dessus).
En conclusion, ce qui signe l'originalité d'une analyse de texte avec SATO, c'est en bonne partie cette démarche itérative qui consiste à explorer le corpus en mode interactif, à revenir sur la démarche suivie à travers l'examen du journal pour finalement cristalliser les stratégies fécondes sous la forme de scénarios.
Ce cadre de travail est complété par diverses possibilités d'intervention sur le poste de travail SATO. Par exemple, il est possible d'exporter ses résultats sur un fichier externe et d'agir très finement sur les divers formats de présentation. Cette exportation peut être commandée au besoin ou elle peut s'effectuer automatiquement afin de conserver une copie des résultats affichés à l'écran. Il est aussi possible d'extraire divers résultats sur un fichier qui pourra être traité par un logiciel externe. Plusieurs modes d'importation des données sont aussi prévus.
Voilà pourquoi le logiciel SATO constitue un outil central pour la construction de dispositifs expérimentaux appliqués à des corpus textuels. Il correspond tout à fait à l'idée que l'on se fait d'un laboratoire, à savoir un ensemble d'outils que l'on peut combiner à loisir. De plus, SATO allie à la fois les avantages d'un système interactif et d'un système à base de commandes. Le mode interactif permet de naviguer rapidement à l'intérieur du matériau textuel. En cela, c'est un outil d'exploration et de découverte. D'autre part, comme ce cheminement laisse une trace dans le journal sous la forme de commandes exécutables, SATO est un outil permettant de construire des dispositifs reproductibles qui pourront prendre place à l'intérieur de protocoles expérimentaux bien ficelés. Au delà du cadre expérimental, SATO se présente comme un logiciel générique permettant de bâtir une variété d'applications spécialisées en ATO, applications destinées à des publics particuliers ou plus novices.
Cette section introduit un certain nombre de considérations méthodologiques sur la notion de texte et de discours. Les remarques qui suivent ont pour objectif de situer l'utilité du logiciel dans le cadre d'une démarche expérimentale en analyse de texte assistée par ordinateur.
Tout projet en analyse de texte est fondé sur un certain nombre d'hypothèses sur la nature du discours dont les textes individuels constituent la manifestation. Ainsi, on peut considérer que les textes rassemblés dans un même corpus pour fin d'analyse devraient, au delà des variations individuelles propres à chaque texte, partager des caractéristiques communes qui les destinent à leur fonction spécifique à l'intérieur du domaine de connaissances auquel ils participent.
En d'autres mots, nous posons l'hypothèse de cohérence du discours social, plus spécifiquement ici, du discours produit dans le cadre d'un domaine du savoir ou d'un forum auquel participe un public donné. À partir de cette hypothèse générale de cohérence, on voudra étudier le fonctionnement discursif en observant une collection de textes individuels. La question de la représentativité des données est donc une des premières questions à poser dans une approche expérimentale. Cette représentativité implique des hypothèses sur l'objet à analyser, sur sa cohérence et sa variabilité.
En termes métaphoriques, nous pouvons imaginer qu'à un espace de pratiques sociales correspond un ou plusieurs espaces discursifs. Il faut donc, dans un premier temps, justifier la constitution (cohérence, pertinence sociale) de l'espace discursif que l'on veut étudier. Ensuite, on doit rassembler un corpus qui soit significatif de cet espace. Cela veut dire que l'on vise à choisir des textes individuels qui se répartissent sur l'ensemble de cet espace. Cela veut dire aussi que l'on doit disposer d'une quantité suffisante de textes pour pouvoir dépister des régularités significatives.
D'un autre côté, il arrive souvent que le choix du corpus à analyser, et son étendue, soit fixé au départ. Il peut s'agir, par exemple, de l'oeuvre d'un auteur. Dans ce cas, les questions de représentativité du corpus vont surtout déterminer la portée des conclusions que l'on pourra tirer de son analyse.
La constitution du corpus implique donc déjà un certain nombre d'hypothèses sur l'existence et les caractéristiques de l'espace discursif que l'on veut analyser. Le protocole expérimental auquel on veut soumettre le corpus implique aussi l'existence d'un modèle interprétatif que l'analyse permettra de corriger et de compléter.
Dans un premier temps, le modèle peut être très sommaire. En fait, il s'agit d'abord d'hypothèses sur la nature des régularités discursives qui seraient associées à une intentionnalité, explicite ou non, des textes. L'objectif est donc de bâtir un protocole expérimental afin d'évaluer l'ampleur des régularités appréhendées et leur caractère explicatif. L'utilisation des outils d'exploration de SATO peut aussi permettre de découvrir des procédés discursifs inattendus susceptibles de suggérer de nouveaux modèles d'interprétation. C'est ainsi que l'on peut non seulement confirmer ou infirmer des modèles interprétatifs existants mais que l'on peut aussi les développer.
L'objectif du dispositif expérimental est de produire des indices textuels, qu'ils soient quantitatifs ou qualitatifs, qui mesurent la présence de ces procédés discursifs. Cependant, il est très difficile et peu naturel de concevoir des indices textuels qui se situent directement dans cet espace linéaire que constitue la séquence de caractères. Voilà pourquoi SATO vise à fournir un appareillage expérimental, un «laboratoire textuel» qui puisse situer le texte dans un espace qui nous soit plus familier. Il est alors plus facile de construire des indices interprétables pour la validation de nos modèles d'interprétation du texte.
C'est ce cadre théorique qui justifie un certain nombre de choix qui sont à la base du logiciel SATO.
SATO répartit ses fonctionnalités en deux modules. On accède au premier module en soumettant un corpus en format texte pour qu'il soit mis en forme dans le plan lexique/occurrences de SATO. Ce module lit les divers documents du corpus et en reconnaît les composantes principales : mots, ponctuations, paragraphes, références de pagination, annotations, etc. Ce traitement constitue une étape préalable dont les résultats sont gardés en permanence dans des fichiers d'un format spécifique à SATO.
Au terme de ce traitement, SATO a construit, à partir des mots du corpus, l'inventaire de toutes les formes lexicales du corpus (dans SATO cet inventaire est appelé lexique du texte), c'est-à-dire le catalogue de l'ensemble des formes (mots, ponctuations, nombres, etc.) contenues dans le texte. Cette première phase est automatique et très rapide.
Après la génération du corpus sous forme de plan lexique/occurrences, on accède au module d'analyse de SATO. Ce module permet à l'utilisateur d'interroger librement son texte et de contrôler pas à pas les diverses étapes de l'analyse. Pour faciliter ce travail, SATO donne la possibilité d'associer aux mots du texte, ou aux formes lexicales, des annotations numériques, symboliques (catégories) ou libres. SATO offre ainsi la possibilité d'ajouter des dimensions au texte pour mieux le caractériser.
On peut imaginer que définir une propriété pour le lexique revient à rajouter une colonne au catalogue des formes du texte. De même, on peut penser que définir une propriété pour le texte revient à rajouter au texte original une ligne sur laquelle on peut inscrire une annotation pour chacun des mots ou segments (titres, sous-titres, lignes, paragraphes, annotations, etc.) du texte. L'intérêt de ces techniques provient surtout du fait qu'on peut les utiliser dans le cadre d'analyses comparatives.
Un lexique, formes lexicales triées dans l'ordre décroissant de leur fréquence, permet déjà de découvrir certaines choses sur le corpus : sa thématique, l'utilisation des marqueurs d'argumentation et d'énonciation, le niveau de la langue (technicité, familiarité), etc. Mais la comparaison de plusieurs lexiques, provenant de plusieurs textes ou parties distinctes d'un même texte, permet le dépistage de régularités ou d'irrégularités significatives. Ainsi, on pourrait comparer des chapitres entre eux ou par rapport à l'ensemble du texte en alignant pour une même forme lexicale, ses fréquences dans les différents chapitres. Il est également possible de définir un sous-texte qui serait composé des phrases où apparaissent un ou plusieurs mots déterminés.
En fait, on peut constituer des sous-textes à partir d'une grande variété de critères et d'annotions résultant d'un processus itératif d'analyse. Ainsi, la comparaison peut s'effectuer sur des sous-textes formés de mots ayant reçu une catégorie particulière. Imaginons, par exemple, que, dans le texte d'une pièce de théâtre, on ait identifié les réparties de chacun des personnages. On pourrait alors définir comme autant de sous-textes les interventions de chacun d'eux. Dans la tradition de la lexicométrie (cf. Lebart et Salem, 1994), l'application d'algorithmes mathématiques à ces tableaux lexicaux offre des possibilités de découverte qui échappent à la lecture linéaire du texte.
Le recours aux dictionnaires, notamment ceux de la base de données lexicales SATO (BDL-SATO pour la langue française), permet une économie considérable lors du repérage des éléments du lexique. On peut, par exemple, ne s'intéresser qu'aux formes nominales, ce qui réduit significativement le nombre de formes lexicales à considérer.
Schématiquement, les étapes d'utilisation du logiciel sont les suivantes :
Il est à noter que les fichiers en format texte lus par le module de génération de SATO ne seront plus utilisés par la suite puisque SATO travaillera à partir d'une représentation du texte utilisant des fichiers dans un format interne au logiciel. Aussi, le texte doit être mis en forme suivant certaines règles de codification dont l'énoncé précède le texte. Il importe en particulier de définir le ou les alphabets utilisés dans le texte. Il est aussi possible de définir des propriétés qui, associées aux mots du texte, vont en compléter la description. Mais il faut noter que c'est surtout au moment de l'analyse que l'on aura à définir des propriétés.
Une fois que le corpus aura été soumis sans erreurs, il est recommandé de faire décrire le texte, le lexique et les propriétés pour vérifier que la codification ne manifeste pas d'anomalies évidentes . Il est aussi recommandé d'examiner le lexique . Par exemple, c'est parmi les lexèmes de fréquence 1, qu'on retrouverait les erreurs de frappe. Pour corriger ces erreurs, il faudra retourner au texte original, corriger les fautes et soumettre le corpus à nouveau.
Dans SATO, le découpage du flot de caractères en formes lexicales se fait au moyen d'une définition d'alphabet qui indique, notamment, quels sont les caractères délimiteurs qui séparent les mots, en plus de l'espace, de la tabulation et du retour à la ligne. L'alphabet est une donnée programmable, c'est-à-dire que l'utilisateur peut, s'il le désire, définir ses propres alphabets. Le repérage des locutions, constituées de plusieurs mots distincts du point de vue des règles orthographiques, peut constituer une première étape de l'analyse textuelle destinée à enrichir le lexique de telle sorte qu'il regroupe les unités lexicales signifiantes d'un point de vue analytique. Une approche possible consiste à bloquer les locutions, c'est-à-dire à lier les mots de telle sorte que SATO puisse les reconnaître comme une seule unité lexicale. L'utilisation de SATO à cette fin est documentée dans la section Tâches /Dépistage des locutions de l'interface intégral.